7. Counting Statistics¶
7.1. Background¶
Quantum mechanical processes are fundamentally random processes. For example one cannot predict at what time exactly an atom in an excited state performs a transition from an excited state to its ground state. What can be calculated is the probability for this process to occur within a certain time interval. Since the lifetimes of excited states in an atom are often very short it is difficult to directly observe the random nature of these processes. However certain nuclear processes occur with such small probabilities that the associated lifetimes are long and their random nature is relatively easy to observe.
7.1.1. Equipment¶
In this experiment you will use a Strontium 90 (\(^{90}Sr\)) source and a Geiger-Mueller (GM) counter. \(^{90}Sr\) is a \(\beta\) emitter in which a neutron inside the nucleus is converted into a proton and an electron and a neutrino are emitted. The electron (historically called a \(\beta\) particle) is detected in the GM counter. The decay scheme is shown in Fig. 7.1.
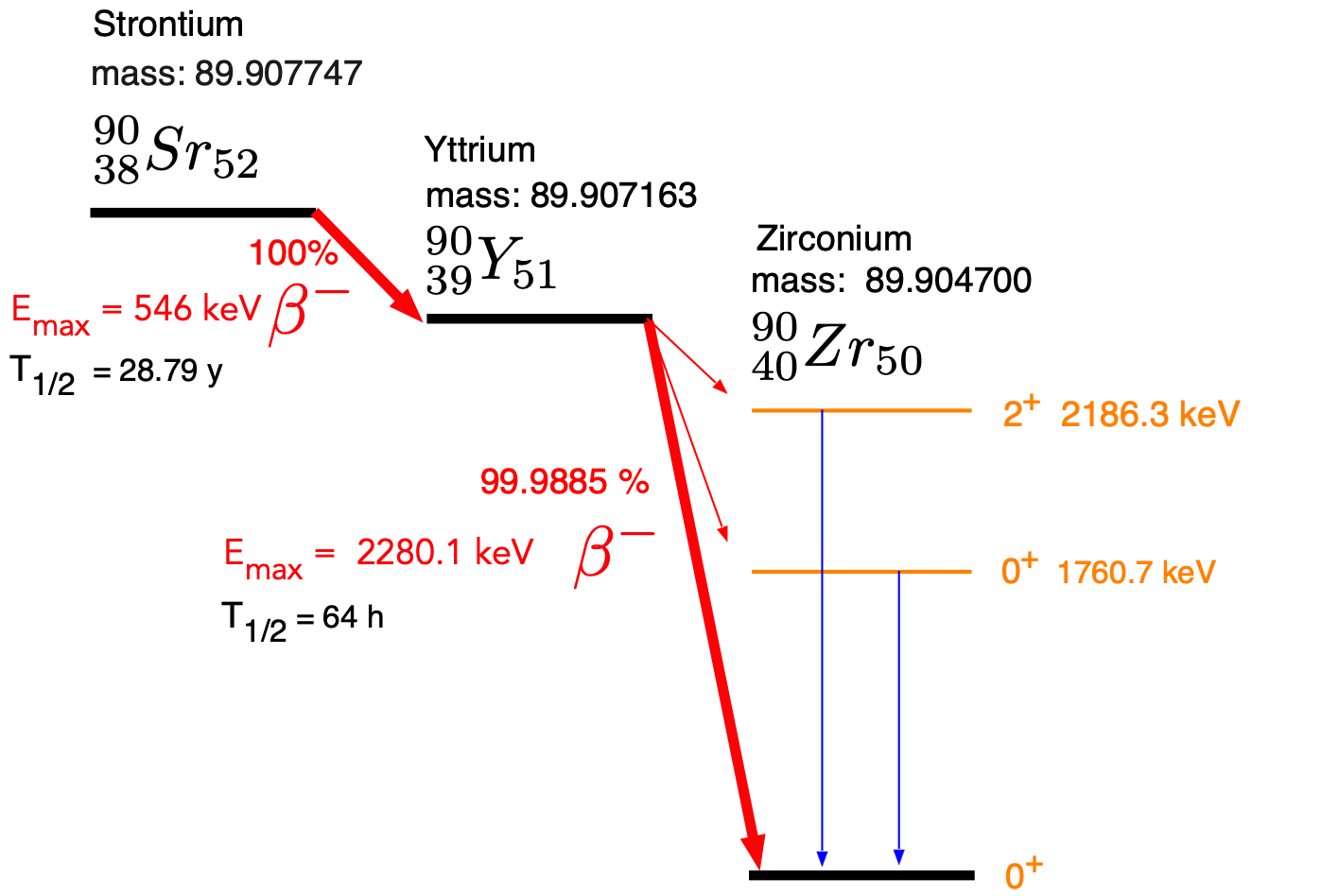
Fig. 7.1 Decay scheme, masses and half lives of the \(^{90}Sr\) \(\beta\)- -decay. The masses are in amu (\(931.49432 MeV/c^2\))¶
The energy spectrum of the emitted electrons is continuous up to a maximal energy pf 2.28 MeV.
A schematic of the GM counter setup is shown in :
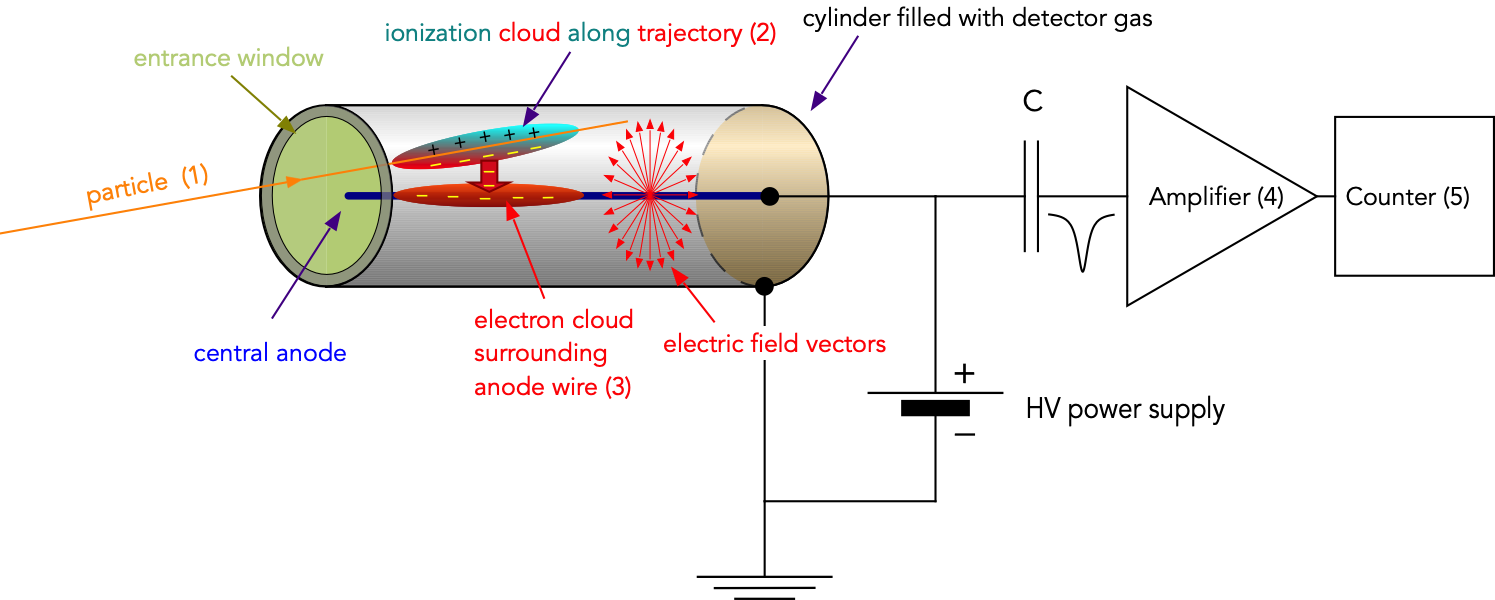
Fig. 7.2 Geiger-Mueller counter operating principle and schematic readout electronic.¶
The detector is basically a gas-filled coaxial capacitor, whith the outer cylinder at ground and the inner central wire at positive high voltage (HV). This produces an electric field between the wire and the cylinder wall (check your intro physics book to learn how the electric field varies as a function of distance from the central wire). An electron or photon enters the counter through a thin entrance window (1). Along its trajectory it collides with gas molecules and ionizes some of them. This results in a cloud of ions and free electrons along its trajectory (2). The electic field produces a force on the electrons towards the central wire and a force on the ions toward the outer wall. Since electrons have a much smaller mass than ions they quickly accelerate toward the central wire. Along their path they continue to collide with gas molcules but initially they do not have enough energy for ionization. Once they are close to the wire the electric field is large enough to allow the electrons to gain enough energy between collisions to ionize more gas molecules resulting in a chain reaction and an avalanche of electrons surrounding the central wire appears. This process is called gas multiplication and gains of up to \(10^6\) can be achieved. The large number of electrons finally produce a current pulse which is amplified and counted by an electronic counter.
7.1.2. Definition of Probability¶
Assume that you make \(N\) independent measurements (e.g. repeat the same measurement again and again). You observe different (for the moment discrete) results \(x_i\) and you find each result \(n_i\) times. The probability to observe the result \(x_i\) is now defined as
For the same set of results we can calculate the mean as follows:
A measure for the spread of the values \(x_i\) one uses the variance defined as follows:
Note that in reality one never has an infinite set of values but one estimates the mean and variance from a finite set of values, e.g. the results from a set of measurements. This is shown below in this description.
7.1.2.1. Rules for calculating with probabilities¶
\(p(x_i) \geq 0\)
If \(x_i\) and \(x_j\) are two results which are mutually exclusive, then \(p(x_i\ or\ x_j) = p(x_i) + p(x_j)\)
The probability for NOT finding the result \(x_i\): \(p(\overline{x_i}) = 1 - p(x_i)\)
If \(y_i\) is another quantity which is independent of \(x_i\) and occurs with the probability \(q(p_i)\), then the probability of finding \(x_i\) and \(y_j\) at the same time is \(P(x_i\ and\ y_j) = p(x_i) \cdot q(y_j)\)
7.1.3. Distributions Functions¶
There are in general two types of random variables, discrete variables as \(x_i, i = 1,2 ...\) and continuous variables \(x\). For a continuous variable one cannot define a probability for a certain exact value \(x_0\) (it would be 0) but one can define the probability for a value being between \(x_0\) and \(x_0 + dx\). This probability is then defined as:
here \(p(x)\) is the probability density.
\(p(x_i)\) is called a distribution function. Under certain
circumstances one can predict the distribution function that will
describe the result of many repetitions of the same measurement. For example, as a
measurement we define the counting of the number of successes
resulting from a number of trials. We assume that each trial is a
binary process that can only have two results: success or
failure. In addition we assume that the probability for an
individual success is constant for all trials.
Examples of measurements that satisfy these conditions are shown in Section 7.1.3.1 below.
7.1.3.1. Binary Processes:¶
Trial |
Definition of Success |
Probability |
|---|---|---|
Tossing a coin |
Head |
1/2 |
Rolling a dice |
6 |
1/6 |
Observing a given
radioactive nucleus
for a time |
The nucleus decays during the observation period |
\(1-e^{-\lambda t}`\) |
7.1.3.2. Binomial Distribution¶
The most general distribution function is the Binomial
Distribution. If the probability for a success (e.g. head when tossing a coin, or a radioactive decay withing a time inetrval \(\delta t\)) is called
\(p\). The probability of finding \(x\) successes in \(n\) trials is given by:
This is the Binomial distribution with the normalization:
and for the mean:
7.1.3.3. Poisson Distribution¶
For most nuclear processes the probabilities (\(p\)) of success are very small and a very large number of trials (\(n\)) are necessary for success; mathematically one can write \(n\rightarrow \infty\), \(p \rightarrow 0\) while \(\mu=np=const.\)
Under these conditions we can rewrite the binomial distribution (7.5) with \(p = \frac{\mu}{n}\):
For \(n\rightarrow \infty\) one can make the following approximations:
Inserting these approximations in the last expression in (7.8) results in the Poission distribution (7.10)
where \(\mu = pn\). The mean can be obtained as before:
and for the standard deviation (the variance) one obtains:
Therefore \(\sigma^2 = \mu\) or \(\sigma = \sqrt{\mu}\). This is a very important result for the determination of uncertainties in counting experiments.
For counting experiments (e.g. counting the number of decays during a fixed time intervall \(\Delta t\)), the mean \(\mu = \bar{N} = \frac{1}{N}\sum n_i\), where \(n_i\) is the number of counts obtained in the \(i^{th}\) measurement. In this case \(\sigma_N = \sqrt(\bar{N})\).
If you just have a single measurement with the result, \(N_{exp}\), and we assume that \(N_{exp}\) represents the mean for this measurement (which is a coarse assumption but the only one you have) then the estimate of the standard deviation for this measurement would be \(\sigma_{N} = \sqrt{N_{exp}}\). This is a really important result which is widely applied.
7.1.3.4. Gaussian or Normal Distribution¶
As the Poisson distribution is a simplified form of the Binomial distribution for small values of \(p\) and \(\mu = np\) if one allows the mean value \(\mu\) to become large the distribution changes into the Gaussian or Normal distribution:
This is still a discrete distribution since the values \(x\) are counts. It has the same properties as the Poisson distribution ((7.11), (7.12)) In this form the distribution is still completely defined by the value of the mean \(\mu = np\). However if the instrument used lost data or has an inefficiency and detects background events as well the counts detected need to be corrected for these problems. In this case the distribution function is no longer determined just by the mean, but by the mean and the standard deviation \(\sigma\).
The distribution function really depends on the deviation \(\epsilon = x - \mu\) and the standard deviation \(\sigma\). One can then consider it as a continuous function of \(t = \epsilon/\sigma\) where \(\epsilon = x - \mu\). One now asks what is the probability for finding a value of \(t\) between \(t\) and \(t + dt\). This is given by \(G(t)dt\) with
where \(0 \leq t \leq \infty\) and \(G(t) = G(\epsilon)\frac{d\epsilon}{dt} = G(\epsilon)\sigma\).
The probability \(f(t_0)\) of finding a value of \(t\) smaller than a certain cut-off \(t_{0}\) one calculates:
With the result that for \(t_0 = 1\) (\(\epsilon = \sigma\)), \(f(t_0) = 0.683\) (about 2/3) and for \(t_0 = 3\) (\(\epsilon = 3\sigma\)), \(f(t_0) = 0.997\). This means that about 2/3 of all results should lie within one standard deviation from the mean value and 99.7 percent within 3 \(\sigma\)!
The goal of the following measurements is to check if indeed results with a very small number of counts are described by Poisson distribution and if the number of counts in the result increases if it follows the Normal distribution. You can then also determine how the observed data rate depends on the distance between detector and source.
Since the Gaussian distribution is a limiting case of the Poisson distribution, the same rules apply for estimating the uncertainty of a counting result:
If you just have a single measurement with the result, \(\color{red} N_{exp}\) , and we assume that \(\color{red} N_{exp}\) represents the mean for this measurement then the estimate of the standard deviation for this measurement is \(\color{red} \sigma_{N} = \sqrt{N_{exp}}\).
7.1.3.5. Estimating Mean and Variance:¶
Most of the time we do not know what the true mean and variance of a underlying distribution for our data is and we have to determine or estimate this information from the available data. When we have set of N data e.g \(x_0, x_1, ... x_N\), such as the results of our 200 measurements, we can estimate the mean by using the well known expression:
An the (unbiased) variance can be estimated using the expression:
Note in this case that if you would create several new set of data (of 200 measurements) your estimated mean and variances would differ slightly from data set to data set.
7.2. Geometry of a Point Source¶
In this experiment we assume the that the \(^{90}Sr\) source is a point source emitting electrons uniformly in \(4\pi\) radians. A detector with an opening area of \(A_d = \pi d^2/4\), where \(d\) is the diameter, and at a distance of \(r\) receives therefore the fraction \(f = \frac{A_d}{4\pi r^2}\) of all the electrons emitted per second. The (old) standard unit of activity is Curie (Ci) where \(1 Ci = 3.7\cdot 10^{10}\) decays per second. From the measurement of particle rate as a function of distance you can estimate the total activity of the source \(S_{Sr}\). The final relation ship between observed count rate, distance and activity in Ci is as follows:
7.3. Experiment¶
Use a \(^{90}Sr\) source, a Geiger-Mueller (GM) tube and the corresponding electronics. Connect the coaxial cable of the GM tube to the input of the counter and set the time interval to 5 seconds. THE END WINDOW IS VERY FRAGILE. DO NOT TOUCH IT.
Determine the detector plateau. The GM tube together with the counting electronics starts to work only above a certain minimal voltage which needs to be determined experimentally. To do this set the counting time to 10 seconds and mount the source as close to the detector as possible (do not damage the thin entrance window!). If you use a small detector (about a diameter of 1”) start with a voltage of 320 V. If you have a bigger detector you need to start at about 450 - 500 V. If the system does not show any counts, increase the voltage by 20 V and try again. Once you obtain counts record the number of counts obtained for this voltage, increase the voltage by 20 V and record the number of counts again. Repeat this process until at some point the number of counts do basically not change anymore. You have now reached a counting plateau. Plot the number of counts as a function of detector voltage. The estimated error in the number of counts is the square root of the counts. Select as an operating voltage a value where the counts do not vary more than typically 1 - 2 times their estimated error. (Typical values for the small detector are 420 V and for the large detectors 740V).
Set the counter at such a distance from the source that you record about 1-2 events in the shortest time period possible. If you still count too much use paper cards as absorbers. Record the results of 200 such measurements.
After finishing the first series set the integration time and distance such that you count between 100 and 200 counts in the shortest time possible. Take another series of 200 measurements.
Obtain about 200 counts for about 6 different distances (see Fig. 7.3), \(r\), between the source and the end window of the GM tube. Make sure that you have no less than 40 counts at the largest distance. Your smallest distance should be about 3 times the diameter of the detector window and your largest should be about 3 times your smallest distance.
Determine the back groundrate by removing the source and counting for 10 minutes. Use this measurement to correct your distance dependent data for background radiation.
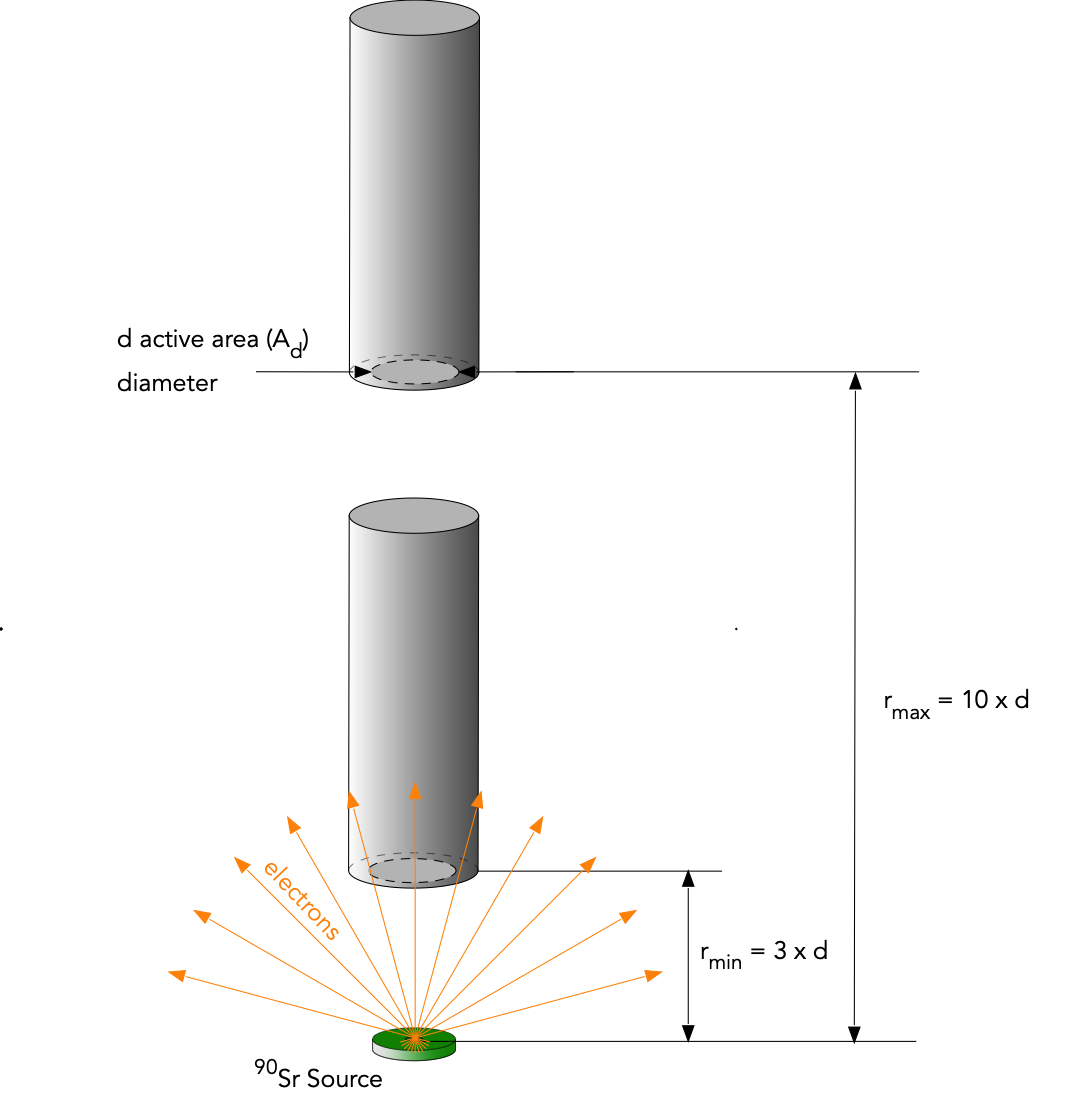
Fig. 7.3 Setup and distances range for distance dependence measurement.¶
7.4. Analysis¶
For the low statistics data calculate the estimated mean and the estimated standard deviation (the variance). Create a histogram with a bin width of 1. Find the value with the highest content (frequency). When you divide the bin contents by the total number of measurements you have an experimental estimate for the probability of each result. Is the result better described by a Poisson distribution or by a Gaussian distribution ? (Hint: to calculate the factorials in the Poisson distribution use the function
factorialfrom thescipy.specialmodule i.e.from scipy.special import factorial). Careful: The Poisson distribution is only defined for integer values of x. How well does your calculated variance agree with your mean? How well does the fitted Gaussian mean agree with your estimated mean?For the high statistics data calculate the estimated mean and the estimated standard deviation (the square root of the variance). Create a histogram with a bin width of 10. Find the value with the highest content (frequency). When you divide the bin contents by the total number of measurements you have an experimental estimate for the probability of each result. Fit a gaussian distribution to the histogram. Compare the fit results to the estimated mean and variance. How well does your calculated variance agree with your mean in this case?
Calculate the background rate \(R_B = \dot{N}_B\) and its uncertainty \(\sigma_R\) from your measurement.
For your distance dependence measurements, calculate the expected number of counts due to background radiation for each measurement \(i\), \(N_{B_i} = R_B\cdot \Delta t_i\) where \(\Delta t_i\) is the integration time for measurement \(i\). Calculate the uncertainty of \(N_{B_i}\). Subtract the estimated number of background events from your measured number of counts and calculate the resulting uncertainty for the corrected number of counts.
From the corrected number of counts, calculate the counts per second for each position, \(\dot{N}\) and its uncertainty. \(\dot{N}\) should decrease as \(1/r^2\), so a graph of \(\dot{N}\) (y-axis) vs. \(1/r^2\) (x-axis) should yield a straight line. Plot these data including error bars and fit a line to them. From the slope of this line and the diameter of the detector you can determine the activity (\(S_{Sr}\)) of the source using (7.19). Using standard error propagation calculate the uncertainty in your result for \(S_{Sr}\). Derive and show the expressions used for determining the source strength from the fitted slope including the calculation of the errors.
7.5. How to create a histogram with a bin-width of 1:¶
You can create a histogram as follows. We assume that Counts contains your high count data, the average value is around 150 and you want a histogram with a bin width of 1 between 140 and 160. Place this function somewhere at the top of your script (but below the import statements):
def set_range(first_bin = 0, bin_width = 1., Nbins = 10):
"""
helper function to set the range and bin width
input : first_bin = bin_center of the first bin, bin_width = the bin width, Nbins = total number of bins
returns: a tuple that you can use in the range key word when defining a histogram.
NOTE: for the histogram use the same number of bins:
example: h = histo( r, range = set_range(-5., 1, 11), bins = 11)
this created a histogram where the first bin is centered at -5. , the next at -4. etc. a total of 11 bins are
created and the bin center of the last one is at 5. = first_bin + (Nbins-1)*bin_width
"""
rmin = first_bin - bin_width/2.
rmax = rmin + Nbins*bin_width
return (rmin,rmax)
Then you can use it as follows to create the desired histogram (e.g. with 11 bins):
number_of_bins = 11
h = B.histo(Counts, range = set_range(first_bin = 140., bin_width = 1, Nbins = number_of_bins), bins = number_of_bins)
You can check the bin centers by entering:
h.bin_center